Unfortunately, a Transformer Model is not a shape-shifting robot from outer space. But it is something even cooler! So much so that Andrej Karpathy tweeted about it.
The Transformer is a magnificient neural network architecture because it is a general-purpose differentiable computer. It is simultaneously:
1) expressive (in the forward pass)
2) optimizable (via backpropagation+gradient descent)
3) efficient (high parallelism compute graph)— Andrej Karpathy (@karpathy) October 19, 2022
In simple terms, think of them as machines that process information step by step. They take in this information, which can be sequences of tokens, words, or numbers, and then pass it through a series of layers that contain self-attention mechanisms. These layers help the transformers understand which parts are essential.
First introduced in 2017, these deep learning models can quickly translate text and voice. An example from the real world is an app that allows tourists to communicate with locals in their language.
This is HUGE! Why?
Because this feature makes it easy to train the model with large amounts of data. For instance, ChatGPT was initially trained with 570GB of text data, including web pages, books, and other sources. However, do keep in mind that it is continually being updated with new data.
Moreover, the self-attention mechanism allows the model to understand long-range dependencies and context better than Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs).?
This type of deep learning has become popular lately, especially in understanding language. The transformer model was first explained in a paper by Google in 2017 called Attention Is All You Need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
This raises the question, what were YOU doing in 2017?
How do Transformer Models work?
So, you want the secret behind this deep-learning architecture. Well, it’s not a secret and is quite simple. There are 3 innovations behind the model.
Positional Encoding
It is a way that allows transformers to understand the order of words in a sentence. Think of it as adding tags to each word to inform the model of where it is in the sentence.
Attention
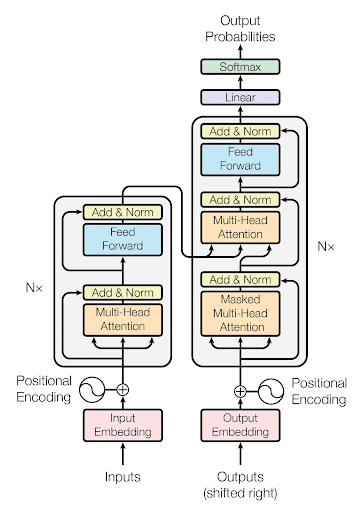
Attention Is All You Need
Think of attention as a spotlight or searchlight, which helps the model focus on important words in a sentence while ignoring less important words.
Self-Attention
Finally, self-attention is when the model pays attention to different parts of the same sentence. It is similar to attention, but here, the model gives an attention score to each word, which helps the model understand the context of the sentence.
9 Steps: How a Transformer Model Works
Input embeddings: When an input is given, words in a sentence are turned into numbers called embeddings. These numbers represent the meaning of the words. For sequences, these embeddings can be learned while training the model or taken from pre-trained word embeddings.
Positional encoding: As mentioned above, these values or tags are added to the embeddings before being fed into the model. These values follow specific patterns to encode positional information.
Multi-head attention: Self-attention mentioned above enables the model to pay attention to different parts of the sentence using multiple “attention heads.” It uses an activation function called the Softmax function to calculate attention weights.
Layer normalization and residual connections: The model uses layer normalization and residual connections to stabilize and speed up training.
Feedforward neural networks: After the self-attention layer, the output is passed through feedforward layers. The model uses these networks to understand complex patterns and relationships in the data.
Stacked layers: By now, you might already know about this: transformer models have layers stacked on top of each other. Each layer processes the output of the previous layer, gradually refining the representations. This stacked-layer approach allows the model to better understand the sentence.
Output layer: For tasks like neural machine translation, a dedicated decoder module can be added on top of the encoder to create the final output sequence.
Training: These models learn by comparing predictions against correct answers and adjusting to make better predictions. Training typically involves optimization techniques like Adam or stochastic gradient descent (SGD).
Inference: Post-training, the model can be used to understand new data and make predictions or representations for the given task.
How Transformer Models Differ From Other Neural Network Architectures
Attention Mechanism: As you already know, self-attention is the most significant part of this model. This lets the model focus on different parts of the input sequence simultaneously. Think of it like reading a book. Where transformers focus on every aspect of the book, including context, RNNs and CNNs focus solely on a single page or image in the book, respectively.
Parallelization: Unlike RNNs, which process input sequences sequentially, transformers can process input sequences in parallel. This leads to faster training and inference times.
Positional Encoding: As explained before, transformers use positional encoding to understand the order of tokens in the input sequence. This method eliminates the reliance upon recurrence, like RNNs.
Global Context: The major problem with RNNs and CNNs, especially for long sequences, is that they have limited access to context and they also tend to forget information from the earlier steps. On the other hand, transformer models have access to the entire input sequence.
Parameter Efficiency: Transformers require fewer parameters than RNNs, making them more parameter-efficient and easier to train.
Versatility: These can be used to perform various tasks, such as text generation and translation, and they can also be used to perform tasks outside of NLP, such as image recognition.
Want to know why it’s so amazing? Check out this video:
What can Transformer Models do?
We touch that transformers are superior to other forms of neural network architectures like Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs). But this begs the question, how exactly are they different? Let’s find out.
Attention Mechanism: As you already know, self-attention is the most significant part of this model. This lets the model focus on different parts of the input sequence simultaneously. Think of it like reading a book. Where transformers focus on every aspect of the book, including context, RNNs and CNNs focus solely on a single page or image in the book, respectively.
Parallelization: Unlike RNNs, which process input sequences sequentially, transformers can process input sequences in parallel. This leads to faster training and inference times.
Positional Encoding: As explained before, transformers use positional encoding to understand the order of tokens in the input sequence. This method eliminates the reliance upon recurrence, like RNNs.
Global Context: The major problem with RNNs and CNNs, especially for long sequences, is that they have limited access to context and they also tend to forget information from the earlier steps. On the other hand, transformer models have access to the entire input sequence.
Parameter Efficiency: Transformers require fewer parameters than RNNs, making them more parameter-efficient and easier to train.
Versatility: These can be used to perform various tasks, such as text generation and translation, and they can also be used to perform tasks outside of NLP, such as image recognition.
What can Transformer Models do?
Continuing on the versatility aspect of transformers, you might be asking, what can they do?
Everything! Except for cleaning your room.
Jokes aside, transformers can perform a wide variety of tasks from translating text and speech in real-time to decode the chains of genes in DNA and amino acids in proteins.
Yes, you read that right. The transformer model can decode DNA, which will help in better diagnoses and drug discovery.
But the capabilities do not end there. These models can also perform tasks like:
Language Translation: Unlike word-for-word translation, transformers can translate the underlying meaning of a sentence. Moreover, it maintains the gendered agreement between words for applicable languages.
Text Generation: By now, you must’ve used generative AI like GPT or at least heard about it. If not, you are still living in the 90s. This architecture can generate coherent sentences, contextually relevant text, and even poems!
Text Summarization: It can also create crisp and concise summaries of lengthy pieces of text in mere seconds.
Question Answering: It can answer questions based on the given context or information. This is why it is being implemented as a virtual assistant or chatbot in various applications.
In addition to the features mentioned, it can perform Sentiment Analysis, Named Entity Recognition, Text Classification, and Language Understanding.
Also, if you are thinking about whether your business needs an AI, check here to know more.
How Businesses Can Leverage Transformer Models
It is not about “how” anymore, honestly. It’s more about “when” a business will utilize transformer models. Since 2017, many businesses have opted for these models like GPT-4, BERT, XLNet, and more in their operations.
Following are some ways businesses can leverage this model:
Natural Language Processing (NLP) Applications:
Transformer models perform NLP tasks like sentiment analysis and language translation exceptionally well. Therefore, businesses can use these models to analyze customer feedback, extract insights from text data, and provide multilingual support.
Chatbots and Virtual Assistants:
In the modern world, even half of small businesses have mobile applications. Therefore, customer support is crucial. Transformer models can be used to implement features like answering queries, scheduling appointments, and assisting customers overall. For instance, Dom, Domino’s Interactive Chatbot allows users to place an order, track an order, and ask FAQs.
Content Generation:
Businesses can also utilize transformers to generate high-quality descriptions for their products, from blogs to image generation. Think of GPT-4 by OpenAI.
Data Analysis and Decision Support:
Thanks to their ability to understand long sequences, they can analyze large volumes of structured and unstructured data to highlight patterns, trends, and insights. Businesses can use this information to make strategic decisions. For instance, Netflix uses transformer models and other machine-learning algorithms to understand user preferences, predict viewing behavior, and optimize recommendations.
Fraud Detection and Security:
Transformers can detect anomalies in transaction data, user behavior, and network activities. Businesses can use these models to detect fraudulent activities in their systems. However, keep in mind that the model must be trained in anomalies and rare patterns.
Limitations of Transformer Models
Computational Resources: Transformer models require a substantial amount of computing power and time, which can become quite expensive, especially for small businesses.
High Memory Requirements: Transformers are quite memory intensive, especially for long sequences of data. This makes them problematic for devices with limited memory, like budget mobile devices.
Fine-tuning: Unless the model was trained for a specific task, adjusting to performing different tasks can be extremely difficult for the pre-trained model.
Limited Interpretability: These models are often referred to as black boxes due to their complex architectures and large number of parameters. This makes it extremely hard to understand why transformers make certain decisions and predictions.
Difficulty with Rare Patterns: Although transformers are excellent at highlighting repetitive patterns, they struggle with low-frequency or rare patterns in data, especially if those patterns are not well represented in training data.
Data Efficiency: To achieve optimal results, transformer models need a ton of labeled data, which can be a problem if you don’t have a lot of good-quality data available.
The History of Transformer Models
What? You thought we wouldn’t mention their history?
2017
As mentioned above, this architecture type came across public in 2017 with Google’s “Attention is All You Need” paper. This revolutionized the field of natural language processing (NLP) and deep learning so much that Google was thinking of naming it “Attention Net”. Not so catchy, huh?
“Attention Net didn’t sound very exciting,” said Vaswani.
2018
Just a year after the release of the transformer model, BERT was introduced, short for Bidirectional Encoder Representations from Transformers. This was perhaps the most advanced and popular transformer-based model for pre-training back in the day.
BERT also proved that one can build great models on unlabeled data.
2019
Seeing their advantages and the success of BERT, it was understood that this is the way forward. This is where new models began to emerge, notably, GPT, XLNet, and Facebook AI.
2020-Present
Now, unsurprisingly, transformer-based models are everywhere! In the field of NLP, it would be a surprise if you found a model that is not based on this architecture. Since 2020, efficiency has been improved with such models and many challenges have been addressed, giving us nearly an error-free experience.
Now, transformer architectures are venturing beyond NLP in sectors like speech recognition, recommendation systems, and reinforcement learning.
The Future of Transformer Models
![]()
Although this architecture was developed with text data in mind, it is now being utilized in other domains. Every major AI model is built using transformers. For instance, MidJourney. It is a platform that creates images from text prompts.
Without a doubt, transformers are remarkable and irreplaceable in what they do. But are they really irreplaceable?
Before 2017, Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs) were considered the greatest thing on the technological front. However, transformer-based models only took 3 years to take over the AI domain. So, it’s only a matter of time before something unique and better emerges that’ll replace transformer models.
But the question is, what?