If you’re using the Internet (which you obviously are; how else are you reading this brilliant article?), you must have heard of something like “Generative AI is taking over the world.”
It is not a false claim or exaggeration by any means because machine learning and generative AI are evolving constantly to the point where we have generative AI capable of generating human-like content, whether it be text, audio, video, or images.
Here, we’ll focus on models that generate images (primarily) and videos.
Diffusion Models – Explained
Think of these models as complex machine learning algorithms that can generate unique and high-quality results similar to the data they were trained on.
Interestingly, they work by destroying the training data gradually and then understanding to recover the original data and transform it into something new and unique. Think of it like adding layers of paper to a painting until it is completely obscured. Then, gradually removing each layer to reveal the original artwork.
Counterintuitive? Not at all! It is brilliant because this method enhances the creativity of the model. Post-training, it can generate new data by putting random noise through the denoising process.
How do Diffusion Models Work?
As mentioned previously, they work by gradually introducing noise to a dataset and then learning to reverse the process. Here’s a step-by-step breakdown of how they work.
Data Preprocessing
Formatting is where it all begins. Before beginning the diffusion process, it is crucial that data must be appropriately formatted before training. This process is known as data preprocessing, and it is done so the model can better understand the data during training. This process is then further divided into four steps.
- Cleaning the data to remove outliers.
- Normalizing the data to ensure consistent scaling of features.
- Augmenting the data to boost diversity, especially for image data
- Standardizing the data to achieve a normal distribution. It is important for handling image data with excessive noise.
NOTE: Different text or image data types may require specific preprocessing steps like addressing class-imbalance issues.
High-quality data is required during training to ensure the model learns functional patterns and generates high-quality images (or other data). For instance, if you want the model to generate an accurate image of a banana, you should train it with detailed images of different types of bananas.
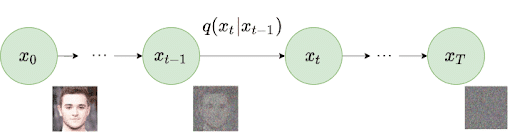
Forward Diffusion Process
It is the process of adding noise to the dataset. The forward diffusion process begins with a sample from a basic distribution, typically Gaussian. The sample then experiences a series of gradual reversible changes, each adding a controlled level of complexity.
Each step’s gradual increase in complexity is often represented as additional structured noise. The model can understand and recreate complex patterns and details in the target distribution by diffusing the initial data through successive steps.
This process transforms these simple beginnings into samples resembling the desired complex data distribution. Even with limited information, detailed results can be achieved.
https://theaisummer.com/static/1f5f940d6d3f1e00b3777066f6695331/073e9/forward-diffusion.png
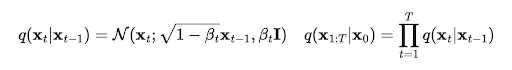
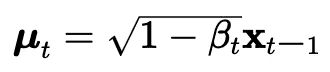
Here, q(xₜ∣xₜ₋₁) is defined by the mean μ.
Reverse Diffusion Process
In this process, the model recognizes distinct noise patterns added at each stage of the noise-introducing phase and begins denoising accordingly. While it may sound simple, it is a rather complex reconstruction. The model predicts and carefully removes the noise at each stage from its acquired knowledge.
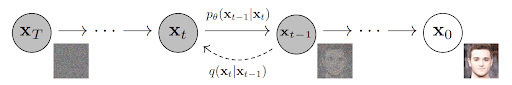
Usually, the neural network is visualized like this:
Understanding Diffusion Model Mechanisms
To better understand how they work, it is also essential to understand the key mechanisms that work together to help the model perform better. These frameworks help the models take simple noise and turn it into a detailed image, making them powerful tools in machine learning. Let’s go through each in detail.
Stochastic Differential Equations (SDEs)
Think of them as guides explaining how noise is gradually introduced into the data. So, why are SDEs important? They provide flexibility to the models to be used for different generative tasks by enabling them to work with varying degrees and types of data.

Score-based Generative Models (SGMs)
These models learn to generate realistic samples by predicting the log-density function (score function) gradient of the data distribution.
In simple terms, these teach the diffusion models to generate high-quality images from noisy data by gradually removing noise. Remember the example of a painting given at the beginning? Think of this part as peeling the layers to reveal the original painting.
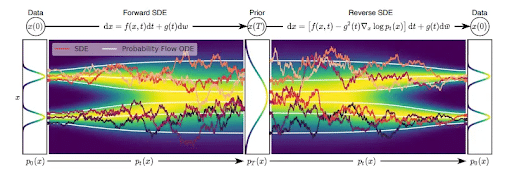
Denoising Diffusion Probabilistic Models (DDPMs)
These models solely focus on removing noise from data based on probabilities. So how do they do it? By making educated predictions about what the original image looked like before adding noise.
They can do it because the training phase teaches DDPMs how noise is added and removed from the original data. This step is crucial when ensuring that the generated outputs resemble the original data.

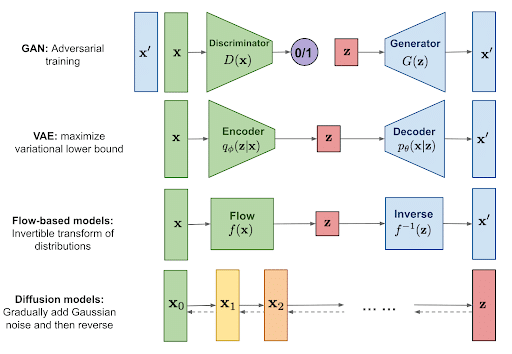
Diffusion Models vs GANs
GANs don’t really stack well in this comparison. But before we jump into that, let’s briefly go over what GANs are.
Generative Adversarial Networks (GANs) are another type of generative model. In these, two neural networks, Generator and Discriminator, are trained simultaneously. While the generator network learns to generate fake data samples that resemble real data, the discriminator learns to distinguish between real and fake data samples.
So why are GANs not regarded as the superior generative AI?
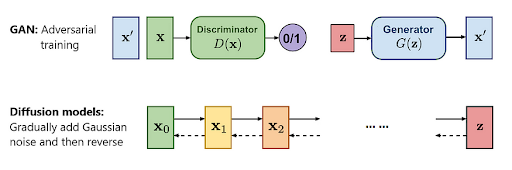
Quality of Output
One huge disadvantage of GANs is that they produce subpar output and cannot produce super-realistic images. This is due to their difficulty in training.
Let’s take an example to understand it better. Let’s say you want to generate images of a realistic cat. During training, the generator in GANs gets better at creating fake cat images that fool the discriminator into thinking they’re real cats, leading to undesired results.
On the other hand, diffusion models will gradually remove noise from a distorted image until a realistic cat image is revealed.
Stability in Training
Diffusion models exhibit more stability during training, whereas GANs often face challenges like mode collapse, where the generator restricts the variety of output samples.
Interpretability of Loss Functions
GANs relying on adversarial training with complex loss functions make interpreting and troubleshooting issues during training difficult. In contrast, diffusion models use more straightforward loss functions, which are easier to understand and optimize.
Loss Functions: It’s a way to evaluate how accurately an algorithm models the dataset. It is like a scorecard, where accuracy grants a higher score.
What can Diffusion Models do?
They have various capabilities that can be applied to different tasks. Such as:
Image Synthesis
Based on their given dataset, they can generate realistic images from scratch. This includes tasks like generating images of objects, animals, landscapes, and more.
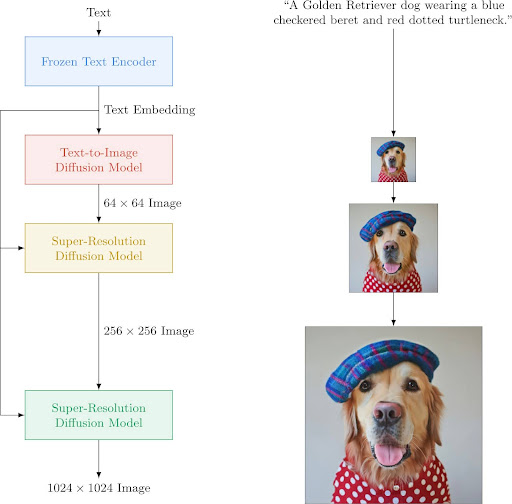
Text-to-Image Synthesis
They can generate images based on textual descriptions. This is the feature that grabbed the attention of the entire world. Some popular examples are Imagen, DALL-E 2, DALL-E 3, Midjourney, and open-source Stable Diffusion.
Here’s an amazing sample from Imagen. The prompt was: A photo of a Corgi dog riding a bike in Times Square. It is wearing sunglasses and a beach hat.
 \
\
Layout-to-Image Generation
They can generate realistic images from basic layouts or structural information. For instance, if you input a rough sketch of a house with trees, the model will generate a realistic image of a house with trees surrounding it.
Inpainting
They can also fill in missing or damaged parts of an image, making them ideal for image reconstruction. For inpainting, think of Adobe Photoshop’s Generative Fill feature that completes the missing part of an image.

Super-Resolution
It is a process of increasing the size and quality of the images, and these models are more than capable of carrying out this task. It is quite useful for improving the quality of low-resolution images, especially the old ones.
How Businesses Can Leverage Diffusion Models
Given the popularity of generative AI, it shouldn’t be surprising that most businesses are utilizing these models.
Here are some cases of how businesses can leverage them further:
Visual Designing
Like Adobe’s Generative Fill feature, these models can be used in graphic design and illustration. They can significantly reduce designers’ workloads and be used to create social media posts, logo designs, branding, and more.
Video Generation
Businesses can use them to generate high-quality videos for marketing, advertising, and more. If you think AI is not capable of doing so, think again. Here are some mind-blowing videos shared by MKBHD, a Tech YouTuber.
I got a rare opportunity to ask OpenAI’s video generation model Sora for some videos this week! I had 3 prompts. Here’s the videos with my prompts and what I learned 🧵
— Marques Brownlee (@MKBHD) February 29, 2024
Animation and Motion Design
What if we tell you that generative AI already creates complete animations? Amazing, right? This can tremendously increase the productivity of motion designers and video editors. Here’s an animation created entirely by generative AI:
Moreover, this can also revolutionize the medical industry by providing detailed and customized animation for medical students.
Video Game Designing
Remember everyone’s childhood favorite Super Mario Bros? Well, guess what? In a study published at the 2023 18th International Conference on Machine Vision and Applications (MVA), generative AI successfully created new levels for the video game by learning from existing game design.
If you are unsure of how to utilize a generative AI for your business or what is the best generative AI for your business. We are here to help.
Top Diffusion Models
Here are some popular AI diffusion tools in the market right now.
Stable Diffusion XL [SDXL]
The latest addition to the Stable Diffusion toolbelt is XL or SDXL. This model can generate realistic faces, accurate text within the images, and more with simple prompts. In addition to text-to-image, it can also carry out tasks like inpainting and outpainting.
Prompt: Elon Musk holding a sign that says “TRY SDXL”

DALL-E 3
DALL-E 3 by OpenAI is similar to SDXL; however, it provides more control to the user. Additionally, it is now natively built-in ChatGPT. Moreover, it declines requests that ask for an image in the style of a living artist.
Prompt: An expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula.

Sora
Another tool by OpenAI is Sora, which is a mind-blowing text-to-video generator that can generate up to minute-long realistic videos. What sets Sora apart from other models is that it understands not just the prompt but also how those things exist in the physical world. Check out what it can do here.
Imagen
Google created this diffusion model, and its ideology, “unprecedented photorealism x deep level of language understanding,” explains why it is so popular.
Midjourney
If you’ve been following the trends, then you know that Midjourney was among the first reliable diffusion models. The great thing about Midjourney is that it can work with long-form prompts. One thing to remember about Midjourney is that it can only be accessed via Discord.
Prompt: Extreme close-up of an eye that is the mirror of the nostalgic moments, nostalgia expression, sad emotion, tears, made with imagination, detailed, photography, 8k, printed on Moab Entrada Bright White Rag 300gsm, Leica M6 TTL, Leica 75mm 2.0 Summicron-M ASPH, Cinestill 800T

Limitations of Diffusion Models
Despite being an amazing generative tool, these models have some limitations.
Computational Resources
They can be quite computationally intensive, especially when dealing with large datasets or high-resolution images, which can be expensive and time-consuming for small businesses.
Domain-Specific Challenges
Although they can generate some impressive results, they can struggle to create images when it comes to specific domains. For example, if you ask them to create an image with specific requirements like text, they fail to generate the desired result.
CoMat
Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
Diffusion models have demonstrated great success in the field of text-to-image generation. However, alleviating the misalignment between the text prompts and images is still challenging. pic.twitter.com/WHCJvx0FfO
— AK (@_akhaliq) April 5, 2024
Data Dependence
Their heavy reliance on high-quality data to generate the desired output can be problematic. Inadequate or biased training samples can lead to less-than-desired outputs. For instance, if the models are trained on AI-generated images, they will fail to create realistic images.
Future of Diffusion Models
Despite leaving the entire world awestruck, diffusion models are still relatively new, with limited adoption and support.
With that said, do keep in mind that they are evolving rapidly. Remember that funny video of Will Smith eating spaghetti? That was in 2023; the new borderline realistic video is from 2024. This massive jump in quality was in just a single year. It’s quite scary if you think about it.
But this rapid evolution makes you wonder what generative models will be capable of in the next decade.